[Philip Sargent, 1 June 2020. Async updates 21 April 2021, HTMX updates 28 Feb.2024]
I don't think writing our own object/SQL code is sensible: there is such a lot going on we would create a large volume of software even if we stick close to the metal. [I could well be wrong. That is Option 1.]
We keep the same architecture as now, and incrementally replace modules that use django/SQL with direct object storage of collections using pickle(), shelve() and json(). Concurrency is not a problem as all data is read-only (this is not entirely true - see below). We keep the url-rewriting and html-template things in django.[and migrate the unit-tests (a recent innovation) from django to be run stand-alone.]
This means that the "django-ness" part of troggle becomes quite small. The more modules we replace, the easier it becomes for new people to work on it - but also the easier it becomes to migrate it to newer django versions. Or the easier it becomes to move entirely from django to Jinja2 [or Mako] + a URL-router [e.g. werkzeug or routes] + a HTTP-request/response system. The data flow through the system becomes obvious to any python programmer with no django knowledge needed.
[This could be harder than it looks if cross-referencing and pointers between collections become unmaintainable - a risk we need to watch. But other people are using Redis for this sort of thing. ]
Being memory-resident, we get a 20x speed increase. Which we don't need.
So the proposed Option 2 looks a bit like this (django is the "flawed supplier" and pickle() is the "new supplier")
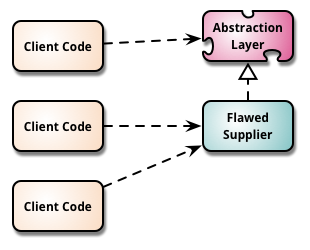 Migrate to Replacement Abstraction Layer
Migrate to Replacement Abstraction Layer
We also use a noSQL db with a direct and easy mapping to python collections. The obvious candidates are MongoDb or the Zope Object Database (ZODB). MongoDb is famous and programmers may want to work on it to get the experience, but ZODB is much closer to python. But ZODB is now rather old, and the Django package django-zodb has not been updated for 10 years. And MongoDb has a bad impedence mismatch: Short answer is you don't use MongoDB with Django which creates a lot of extra pointless work. If we ever need atomic transactions we should use a database and not try to fudge things ourselves, but not either of those. [This needs to be explored, but I suspect we don't gain much compared with the effort of forcing maintainers to learn a new query language. Shelve() is already adequate.]
We migrate to an "improved Django" or a "Django-lite". Django is a massive system, and it is moving with agility towards being more asynchronous, but there are already competing projects which do much the same thing, but in a cleaner way and (being 15 years younger) without the historical baggage and cutting out a lot of now-uneeded complexity. This looks like being a very hopeful possibility. Sanic and Quart look like being the first of a new generation.
The driver for these new Django clones is the asynchronous capabilities in python 3.4 and the ASGI interface for web workers which replaces WSGI. These will have much the same effect on python as Node.js had on JavaScript.
But we should not be in too much of a hurry. It will take Sanic (and similar) years to get to a state where things don't break between versions horribly every 6 months. We lived through that nastiness with Django 2006-2016 and we don't want to fall into the same mess again. Django has only just got sensibly mature and has stopped breaking so much with every new release.
A real architectural option would be to move to Redis as an in-memory database instead of using MariaDB. We don't need a fully-fledged database and these new frameworks are less closely tied to having a SQL database and object-request broker (ORM) than Django is. This ties in neatly which Option 2 above: reduce our use of the database functions within Django to vanishing point. [Oops. That would be a mistake. It is the SQL database that handles all the multi-user non-interference, not Django. So unless we want to roll our own real-time software synchronisation.. Better not go there.]
ASGI, which Dango supports from v3.2 too, has the interesting effect that we no longer need a webserver like Apache or nginx to buffer requests. We can use very lightweight uvicorn instead.
We need to de-cruft troggle *first*: remove 'good ideas' which were never used, trim redundancies and generally reduce it in size significantly.
We should have a good look at making a list of functions that we will drop and some we replace by parsing cavern output and some we calculate during importing/reading svx files.
Documentation and a working list of on-going programming projects is the key to keeping troggle in a state where someone can pick it up and do a useful week's work, e.g. extracting the parsed logbooks to use shelve() storage throughout instead of SQL. The next time someone like Radost comes along during the next 5 years we want to be able to use them effectively.
[Decrufting and refactoring has been continuous since 2020. The ExpeditionDay class was refactored away and many unused properties of classes have been removed. DB query optimisation is only just beginning in 2023 though.]
We should probably review and revise all the over-complex templates, originally written in 2006, which do serious amounts of database querying, and linked object sub-querying, within the template code. This is a nightmare to maintain and debug.
A possible goal would be to create all the data that will be displayed in a page as dictionaries - generated by obviously simple python, with
some Django query optimisations if necessary - which are then handed as 'context' to the Django page template (those files in
troggle/templates/xxx.html), instead of using the Django-specific database object requests within the template sublanguage, e.g.
{% if persondate.2 %}
<td class="survexblock"><a href="{% url "svx" persondate.2.survexfile.path %}">{{persondate.2.name}}</a></td>
{%comment%}
<td class="roles" style="padding-right: 3px; text-align:right">
{% for survexpersonrole in persondate.2.survexpersonrole_set.all %}
{{survexpersonrole.nrole}}
{% endfor %}
</td>{%endcomment%}
<td style="text-align:right">
{{persondate.2.legslength|stringformat:".1f"}} m
</td>
{% else %}
<td colspan="3"> </td>
{% endif %}
Multi-user synchronous use could be a bit tricky without a solid multi-user database sitting behind the python code. So removing all the SQL database use may not be what we want to do after all.
Under all conceivable circumstances we would continue to use WGSI or ASGI to connect our python code to a user-facing webserver (apache, nginx, gunicorn). Every time a webpage is served, it is done by a separate thread in the webserver and essentially a new instance of Django is created to serve it. Django relies on its multi-user SQL database (MariaDB, postgresql) to ensure that competing updates by two instantiations of itself to the same stored object are correctly atomic. But even today, if two people try to update the same handbook webpage, or the same survex file, at the same time we expect horrible corruption of the data. Even today, with the SQL database, writing files is not coded in a properly multi-user manner. We should write some file lock/serializer code to make this safe.
The move by Django from single-threaded WSGI to asynchronous ASGI began with v3.0 and for 'views' almost complete in 3.2. This makes the server more responsive, but doesn't really change anything from the perspective of our need to stop users overwriting each others' work. If we just store everything in in-memory dictionaries we may need to write our own asyncio python to do that synchronization. That would be a Bad Thing as we are trying to make future maintenance easier, not harder. But it looks like Redis could be the solution for us.
[ Redis does multi-user concurrency (which is what we need), but most people don't use it like that.
Nearly everyone who uses Redis with Django uses it as a page cache, not as the fundamental store. So public
experience is likely to be less useful than we may hope. Learning to use Redis would probably also mean getting to grips with
Django's existing cache system,
which is complex and which we don't use.
NB We do cache one page per expedition, but explictly in our own python code. So this is a per-process cache which is good for one
person's intensive use, much like Django's
Local-memory caching ]
There is not yet a front-end (javascript or WebAssembly) framework on the client, i.e. a phone app or webpage, which is stable enough for us to commit effort to (we managed to remove all the jQuery by using recent HTML5 capabilities). Flask looks interesting (but maybe is only simpler when starting a new project and doesn't scale to complexity the way Django does, but maybe in 2025 we could see a good way to move all the user interface (rewritten to be GIS-centric?) to the client (re-written in Typescript or Dart) and just have an API on the server. [We already have a proof of principle JSON export API working, see Troggle JSON.]
Modern JavaScript frameworks support dynamic 'single-page websites' where all the component parts are fetched and replaced asynchronously (this used to be called AJAX when it first appeared in 1999). This is fundamentally different from how Django was originally designed: using public URLs connected to code which produces a complete webpage based on a single template. Django can interoperate with dynamic systems but support will become increasingly baroque I imagine.
New functionality: e.g. making the whole thing GIS-centric is a possibility. A GIS db could make a lot of sense. Expo has GIS expertise and we have a lot of badly-integrated GPS data, so this needs a lot of thinking to be done and we should get on with that.
We will also need an API now-ish, whatever we do, so that keen kids can write their own special-purpose front-ends using new cool toys. Which will keep them out of our hair. We can do this easily with Django templates that generate JSON, which is what CUYC do. We already have some of this: JSON export.
We have been waiting for more than a decade and a half for the JavaScript Framework mess to sort itself out. We want to see where we could sensibly move to a front-end+back-end architecture, instead of redrawing every screen of data on the server (see above "Things that could be a bit sticky 2 - front-end code").
In 2024 it now looks as if we may be able to stretch the current architecture into a post-Javascript era entirely because Webassembly continues to develop rapidly.
HTMX now looks like it may evolve into replacing large chunks of what is now done with JavaScript packages (Angular, React, Vue.. and jQuery before them). See Django/HTMX article (5 Feb.2024).
Andy Waddington, who wrote the first expo website in 1996, mentioned that he could never get the hang of Django at all, and working with SQL databases would require some serious book-revision:
So a useful goal, I think, is to make 'troggle2' accessible to a generic python programmer with no specialist skills in any databases or frameworks. Put against that is the argument that that might double the volume of code to be maintained, which would be worse. Nevertheless, an aim to keep in mind. But even 'just Python' is not that easy. Python is a much bigger language now than it used to be, with some increasingly esoteric corners, such as the new asyncio framework..