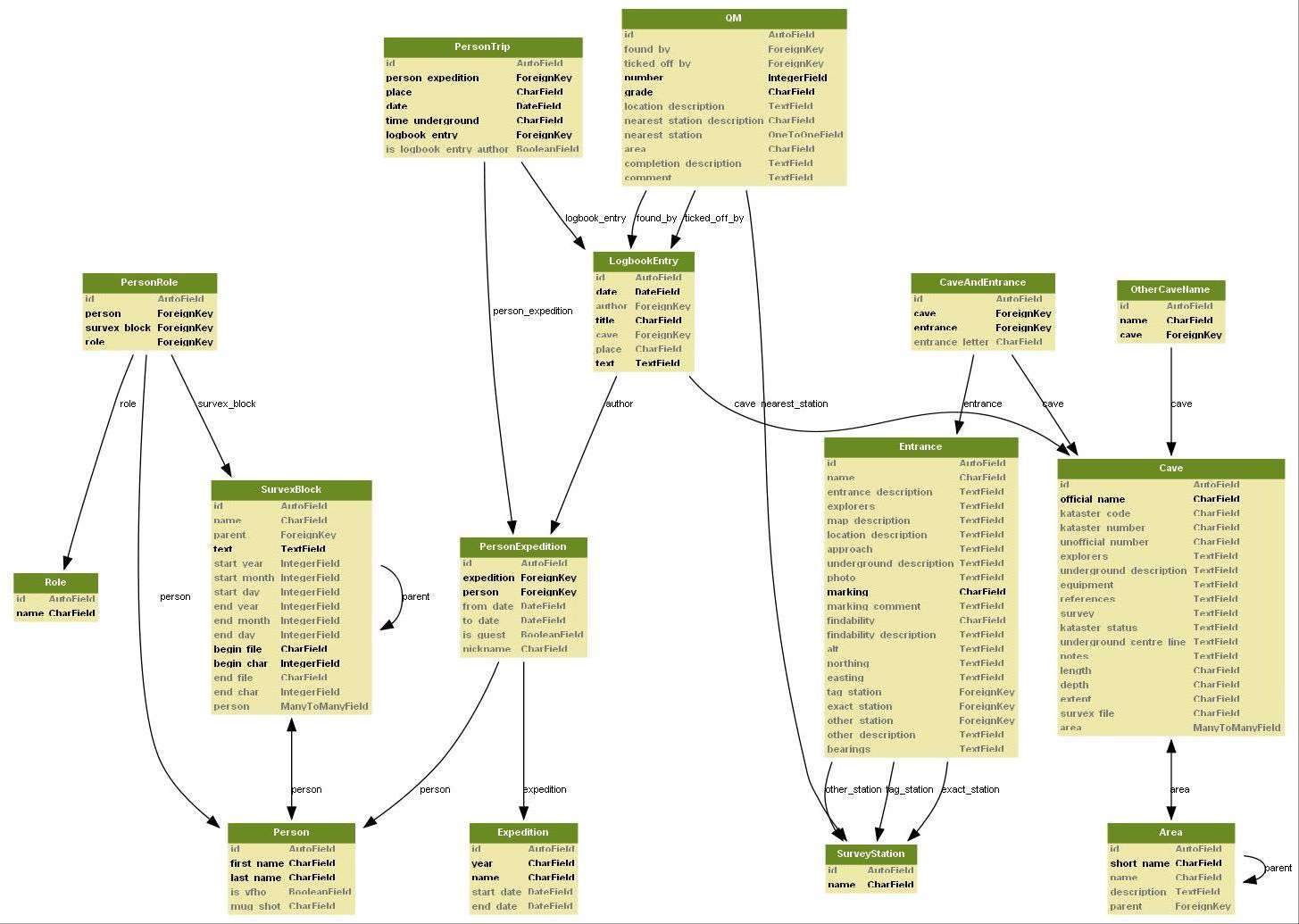
The core of troggle is the data architecture: the set of tables into which all the cave survey and expo data is poured and stored. These tables are what enables us to produce a large number of different but consistent reports and views.
Read the proposal: "Troggle: a novel system for cave exploration information management", by Aaron Curtis. But remember that this paper is an over-ambitious proposal. Only the core data management features have been built. We have none of the person management features and only two forms in use: for entering cave and cave entrance data.
ALSO there have been tables added to the core representation which are not anticipated in that document of this diagram, e.g. Scannedimage, Survexdirectory, Survexscansfolder, Survexscansingle, Tunnelfile, TunnelfileSurvexscansfolders, Survey. See Troggle data model python code (3 April 2020).
There are only two places where this happens. This is where online forms are used to create cave entrance records and cave records. These are created in the database but also exported as files so that when troggle is rebuilt and data reimported the new cave data is there.