 Migrate to Replacement Abstraction Layer
Migrate to Replacement Abstraction Layer
[Philip Sargent, 1 June 2020. Async updates 14 April 2021]
I don't think writing our own object/SQL code is sensible: there is such a lot going on we would create a large volume of software even if we stick close to the metal. [I could well be wrong. That is Option 1.]
We keep the same architecture as now, and incrementally replace modules that use django/SQL with direct object storage of collections using pickle(), shelve() and json(). Concurrency is not a problem as all data is read-only (this is not entirely true - see below). We keep the url-rewriting and html-template things in django.[and migrate the unit-tests (a recent innovation) from django to be run stand-alone.]
This means that the "django-ness" part of troggle becomes quite small. The more modules we replace, the easier it becomes for new people to work on it - but also the easier it becomes to migrate it to newer django versions. Or the easier it becomes to move entirely from django to Jinja2 + a URL-router + a HTTP-request/response system. The data flow through the system becomes obvious to any python programmer with no django knowledge needed.
[This could be harder than it looks if cross-referencing and pointers between collections become unmaintainable - a risk we need to watch.]
Being memory-resident, we get a 20x speed increase. Which we don't need.
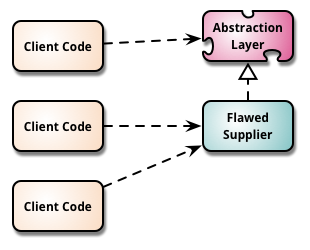
So the proposed Option 2 looks a bit like this (django is the "flawed supplier" and pickle() is the "new supplier")
Migrate to Replacement Abstraction Layer
We also use a noSQL db with a direct and easy mapping to python collections. The obvious candidates are MongoDb or the Zope Object Database (ZODB). MongoDb is famous and programmers may want to work on it to get the experience, but ZODB is much closer to python. But ZODB is now rather old, and the Django package django-zodb has not been updated for 10 years. And MongoDb has a bad impedence mismatch: Short answer is you don't use MongoDB with Django which creates a lot of extra pointless work. If we ever need atomic transactions we should use a database and not try to fudge things ourselves, but not either of those. [This needs to be explored, but I suspect we don't gain much compared with the effort of forcing maintainers to learn a new query language. Shelve() is already adequate.]
We need to de-cruft troggle *first*: remove 'good ideas' which were never used, trim redundancies and generally reduce it in size significantly.
We should have a good look at modifying everything so that we do not read in every survey station. This means making a list of functions that we will drop and some we replace by parsing cavern output and some we calculate during importing/reading svx files.
Documentation is the key to keeping troggle in a state where someone can pick it up and do a useful week's work, e.g. extracting the parsed logbooks to use shelve() storage throughout instead of SQL. The next time someone like Radost comes along during the next 5 years we want to be able to use them effectively.
Multi-user synchronous use could be a bit tricky without a solid multi-user database sitting behind the python code. So removing all the SQL database use may not be what we want to do after all.
Under all conceivable circumstances we would continue to use WGSI or ASGI to connect our python code to a user-facing webserver (apache, nginx, gunicorn). Every time a webpage is served, it is done by a separate thread in the webserver and essentially a new instance of Django is created to serve it. Django relies on its multi-user SQL database (MariaDB, postgresql) to ensure that competing updates by two instantiations of itself to the same stored object are correctly atomic. But even today, if two people try to update the same handbook webpage, or the same survex file, at the same time we expect horrible corruption of the data. Even today, with the SQL database, writing files is not coded in a properly multi-user manner. We should write some file lock/serializer code to make this safe.
The move by Django from single-threaded WSGI to asynchronous ASGI began with v3.0 and for 'views' almost complete in 3.2. This makes the server more responsive, but doesn't really change anything from the perspective of our need to stop users overwriting each others' work. If we just store everything in in-memory dictionaries we may need to write our own asyncio python to do that synchronization. That would be a Bad Thing as we are trying to make future maintenance easier, not harder.
There is not yet a front-end (javascript) framework on the client, i.e. a phone app or webpage, which is stable enough for us to commit effort to. Bits of troggle use very old jQuery ("edit this page", and the svx file editor) , and Flask looks interesting (but maybe is only simpler when starting a new project and doesn't scale to complexity the way Django does, but maybe in 2025 we could see a good way to move all the user interface (rewritten to be GIS-centric?) to the client (re-written in Typescript or Dart) and just have an API on the server. [We already have a proof of principle JSON export API working, see Troggle JSON.]
Modern JavaScript frameworks support dynamic 'single-page websites' where all the component parts are fetched and replaced asynchronously (this used to be called AJAX when it first appeared in 1999). This is fundamentally different from how Django was originally designed: using public URLs connected to code which produces a complete webpage based on a single template. Django can interoperate with dynamic systems but support will become increasingly baroque I imagine.
New functionality: e.g. making the whole thing GIS-centric is a possibility. A GIS db could make a lot of sense. Expo has GIS expertise and we have a lot of badly-integrated GPS data, so this needs a lot of thinking to be done and we should get on with that.
We will also need an API now-ish, whatever we do, so that keen kids can write their own special-purpose front-ends using new cool toys. Which will keep them out of our hair. We can do this easily with Django templates that generate JSON, which is what CUYC do. We already have some of this: JSON export.
Andy Waddington, who wrote the first expo website in 1996, mentioned that he could never get the hang of Django at all, and working with SQL databases would require some serious book-revision:
So a useful goal, I think, is to make 'troggle2' accessible to a generic python programmer with no specialist skills in any databases or frameworks. Put against that is the argument that that might double the volume of code to be maintained, which would be worse. Nevertheless, an aim to keep in mind. But even 'just Python' is not that easy. Python is a much bigger language now than it used to be, with some increasingly esoteric corners, such as the new asyncio framework..