

Troggle is made up of three large chunks:
The core of the troggle software is the data architecture: the set of tables into which all the cave survey and expo data is poured and stored. These tables are what enables us to produce a large number of different but consistent reports and views.
Also there have been tables added to the core representation which are not included in this old diagram, e.g. Scannedimage, Survexdirectory, Survexscansfolder, Survexscansingle, Tunnelfile, TunnelfileSurvexscansfolders, Survey. See Troggle data model python code (15 May 2020) and click on the Class Diagram below on the right.
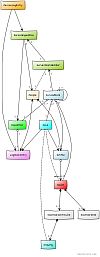
(Click to enlarge)
The reasons why we have an online system at all are described in our website history.
There is an introductory article "Troggle: a revised system for cave data management".
Troggle is written in Python (about 11,000 lines excluding comments) and is built on the Django framework. Before starting to work on Troggle it might be a good idea to run through an initial install and exploration of a tutorial Django project to get the Django concepts bedded down - which are not at all obvious and some exist only within Django.
Django is the thing that puts the survey data in a database in a way that helps us write far less code to get it in and out again, and provides templates which make it quicker to maintain all the webpages.  See the django design philosophy for why we chose it: while django comes with a full stack (db, request/response, URL mapping, HTML templates) the layers of the stack are independent and individually replaceable.
See the django design philosophy for why we chose it: while django comes with a full stack (db, request/response, URL mapping, HTML templates) the layers of the stack are independent and individually replaceable.
We have to keep up to date with new rleases of django, see Upgrading Django for Troggle.
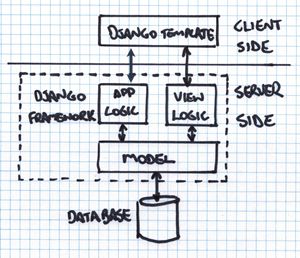
To understand how troggle imports the data from the survex files, tunnel files, logbooks etc., see the troggle import (databaseReset.py) documentation.
The following separate import operations are managed by the import utility (databaseReset.py):
There are only four places where this happens. This is where online forms are used to create cave entrance records and cave records, where a form is used to record the information about a wallet. These are created in the database but also exported as files so that when troggle is rebuilt and data reimported the new cave data is there.
Any page in this handbook, and any logbook entry, can also be edited online and the page is saved as a file - and registered with the version control system.