 The "data maintenance" manual is where to look for help when things go wrong: the data has been entered incorrectly, or software has crashed due to corrupt input data.
The "data maintenance" manual is where to look for help when things go wrong: the data has been entered incorrectly, or software has crashed due to corrupt input data.
Surveying and recording survey data is the primary reason all this exists. The "survey handbook" part of this handbook gives instructions to beginners for how to record discoveries and surveys. The "data maintenance" manual is where to look for help when things go wrong: the data has been entered incorrectly, or software has crashed due to corrupt input data. +
Surveying and recording survey data is the reason all this exists. The "survey handbook" part of this handbook gives instructions to beginners for how to record discoveries and surveys.
The "data maintenance" manual is where to look for help when things go wrong: the data has been entered incorrectly, or software has crashed due to corrupt input data.
The "system maintenance" manual may of interest to a caver who wonders how it is all put together but should not be needed by most people.
-A fuller list of "How do I..." instruction pages are on the handbook opening page. If you are new to this you may need a beer. +A fuller list of "How do I..." instruction pages are on the handbook opening page. If you are new to this you may need a beer. A very fine place for a beer is the Panorama Restaurant at the top of the toll road - as illustrated.
We have an Overview Presentation (2015: many parts out of date) diff --git a/handbook/survey/drawup.htm b/handbook/survey/drawup.htm index 969cd2fbb..2f392ec9d 100644 --- a/handbook/survey/drawup.htm +++ b/handbook/survey/drawup.htm @@ -53,7 +53,7 @@ as the scanned notes, i.e. (for wallet #19) you would put them in: /home/expo/expofiles/surveyscans/2018/2018#19/ - +(but this is not where you will put your finished drawings.)
The tunnel (or therion) files should NOT stored in the same folder as the scanned notes. They will eventually be uploaded to the version control repository drawings -but for a first attempt store them on the expo laptop in /home/expo/drawings/{cavenumber}. +but for a first attempt store them on the expo laptop in /home/expo/drawings/{cavenumber}. Look at what is in there already and ask someone whcih directory to put them in. It will probably be a folder like this: -/home/expo/drawings/264-and-258/toimport/ . + +/home/expo/drawings/264-and-258/toimport/ +
Take the printed centre lines and redraw the survey round it, working from the original sketches as if this was to be the final published survey. You @@ -121,10 +123,11 @@ which will be encountered (eg. if it is a climb, are bolts going to be needed ? If a dig, is it a few loose boulders or a crawl over mud?)
The actual published cave-survey is produced by software these days. These notes come from a different age but reading them will make your tunneling better - and more polished. + and more polished: +
Drawing a cave entirely by hand is not easy but anyone can learn to do it. Read the brief Cave Mapping - Sketching the Detail" 5-page llustrated guide by Ken Grimes which makes everything clear. @@ -160,6 +163,8 @@ experience: it's now late April 2004, and the 204 survey is only just approaching completion. This shows how easy it is for these things to go wrong. The chief problems were a change of software and the fact that the Expo printer broke down last summer, so a number of surveys never got drawn up. --> +
Back to the previous page in this sequence Starting a new survex file.
Now go the the next page in this sequence Creating a new rigging guide".
diff --git a/handbook/survey/why.htm b/handbook/survey/why.htm
index e86f7b27c..383214284 100644
--- a/handbook/survey/why.htm
+++ b/handbook/survey/why.htm
@@ -19,6 +19,10 @@ didn't. Without detailed recording and surveying of the caves, it would
rapidly become more difficult to find new passage, or to be sure that round
the next corner wouldn't be a load of previous explorers' footprints.
 +
+
The main aim of the expedition is to explore new passages - to boldly explore what noone has seen before. Indeed, in many cases, what noone even suspected was there. This is the fun and excitement of expo, so why spoil it diff --git a/handbook/troggle/archnotes.html b/handbook/troggle/archnotes.html new file mode 100644 index 000000000..d5600d84d --- /dev/null +++ b/handbook/troggle/archnotes.html @@ -0,0 +1,314 @@ + + +
+ +Assumptions (points to necessarily agree upon) +
Two page preliminary design document for 'caca' (Cave Catalogue) rev.2 2013-07-26 by Wookey (copied from http://wookware.org/software/cavearchive/caca_arch2.pdf) + + +
This is likely to change with structural change to the site, with style changes which we expect to implement and with the method by which the info is actually stored and served up.
+... and it's not written yet, either :-)
+CUCC still has an archive list of things that at one time were live tasks: +from camcaving.uk/Documents/Expo/Legacy/Misc/... and that page is reproduced in the table below (so don't worry if the URL link goes dark when CUCC reorganise their legacy pages). +
Troggle is a system under development for keeping track of all expo data in a logical and accessible way, and displaying it on the web. At the moment, it is [no longer] under development at http://troggle.cavingexpedition.com/ + +But note that this is Aaron's version of troggle, forked from the version of troggle we use. Aaron uses this for the Erebus expedition. +
+Note that the information there is incomplete and editing is not yet enabled. +
+Feature |
+ Old expo website |
+ Troggle: planned |
+ Troggle: progress so far |
+
|---|---|---|---|
Logbook |
+ Yes; manually formatted each year |
+ Yes; wiki-style |
+ Start at the front page, troggle.cavingexpedition.com/ [1] and click to logbook for year. The logbooks have been parsed back to 1997. |
+
Cave index and stats generated from survex file |
+ Yes |
+ Yes |
+ + |
Survey workflow helper |
+ Yes; minimal. surveys.csv produced an html table of whose surveys were not marked “finished” |
+ Yes. Makes table of surveys per expo which shows exactly what needs doing. Displays scans. Integrated with survex, scanner software, and tunnel. |
+ See it at troggle.cavingexpedition.com/survey . Be sure to try a recent year when we should have data. Survex, scanner, and tunnel integration still needs doing. |
+
QM lists generated automatically |
+ Depends on the cave. Each cave had a different system. |
+ Yes; unified system. |
+ Done, but only 204 and 234 Qms have been imported from old system so far. No view yet. |
+
Automatic calendar for each year of who will be on expo when |
+ No, manually produced some years |
+ Yes |
+ Done; see troggle.cavingexpedition.com/calendar/2007 (replace 2007 with year in question) |
+
Web browser used to enter data |
+ No |
+ Yes |
+ Everything can be edited through admin, at troggle.cavingexpedition.com/admin . Ask aaron, martin, or julian for the password if you want to have a look / play around with the admin site. Any changes you make will be overwritten. Eventually, data entry will probably be done using custom forms. + |
+
Cave and passage descriptions |
+ Yes, manually html coded. |
+ Yes, wiki-style. |
+ Not done yet. |
+
Expo handbook |
+ Yes, manually html coded. |
+
|
+ Not done yet. |
+
Table of who was on which expo |
+ Yes |
+ Yes |
+ Data has been parsed, this view hasn't been written yet. |
+
Signup form, System for keeping contact, medical and next of kin info |
+ No |
+ Yes |
+ Signup form should be ready by 20 Jan. |
+
Automated photo upload and gallery |
+ No; some manual photo galleries put together with lots of effort |
+ Yes |
+ Photo upload done, gallery needs writing. |
+
Search |
+ No |
+ Yes |
+ + |
+ckan is something like this - could we use it? +esri online + +CUCC (troggle) http://cucc.survex.com/ - this site. +virgina caves database (access+arcgis) (futrell) +each country database +Austria (spelix) ( www.spelix.at/ +UK cave registry +mendip cave registry: (access) www.mcra.org.uk/wiki/doku.php +White mountains database (gpx + google earth) +Matienzo (?) +Fisher ridge (stephen cladiux) +hong meigui (erin) (ask erin later) +Wikicaves www.grottocenter.org/ + multilingual, slippymap, wiki data entry. includes coordinate-free caves. + focus on sport-caving type info (access, basic gear list, overall description, bibliography) + e.g. australians only publish coordinates to nearest 10km +turkey www.tayproject.org. + +www.uisic.uis-speleo.org/contacts.html change link. no-one looks for list of databases under 'contacts' + +graziano ferrari northern italy list (access + google earth) ++ +
+Generally I'd like to find some people (geeks) that share these technical +ideas: (1) store things in a file system, (2) use XML, (3) do not aim too high +(do not try designing a general system for handling all caving-related data +for the whole world). + +If I could find some people that agree with this, then we could try to reach a +compromise on: +(1) how do we store our data in a file system, +(2) how do we use this XML (let's do a common spec, but keep it simple) +(3) how do we aim not too high and not end up dead like CaveXML :) + +After we do that, everyone goes away to do their own projects and write their +own code. Or maybe we have some degree of co-operation in actually writing the +code. Normal life. But the idea is that all geeks working on "cave inventory" +and systems making extensive use of cave inventories try to adhere to this +framework as much as possible. So that we can then exchange our tools. + +I think things like "which revision system do we use" or "do we use web or +Python" are really secondary. Everyone has their own views, habits, +backgrounds. + +My idea is to work on this in a small group (no more than a few persons) - to +get things going fast, even if they are not perfect from the beginning. If it +works, we try to convince others to use it and maybe push it through UIS. ++ +
+forms +----- +1) members read/write folk.csv and year/members +2) cave read/write cave_data, entrance_data, surveys/pics +3) trips -> logbook , QMs, or surveys (more than one survey or location possible) +4) logbook reads/write year/logbook +5) survey +6) prospecting app + +forms show who is logged in. + +databases +--------- +trips, read from + logbook entry + folder year#index + .svx files + description + QMs + +members (cache from form) + +caves + caves_data + entrance_data + +storage: + expoweb + data/ + cave_entrances + caves + descriptions + + loser + foo.svx ++ + +
+frontpage +--------- +quick to load: +Links: + Caves number, name, location + Years + Handbook + Data Entry + Main Index + +Slippy map: + Indexes to cave page + +Cave page: + Access, description, photos, QMs, Survey + +Years: + Logbooks/surveynotes/survexdata/people matrix + Documents + +Data Entry: + Logbook entry + Survey data + Survey Notes + Cave description + QMs + Photos + New cave + +Backend datafiles: + caves/ + cave_entrance + cave_data + directory of info + + years/ + year/ + logbook + pubs/ + reports + admin/ + lists + who_and_when + travel + jobs + + surveyscans/ + year/ + index + #num + handbook/ + (all static info) + +Storage: + non-html or > 280K go in 'files' (PDF, PNG, JPEG, DOC, ODF, SVG) + convert small 1024x768 version into website by default. (matching structure? ++ +
Since 2008 we have been keeping detailed records of all data management system updates in the version control system. +Before then we manually maintained a list of updates which are now only of historical interest. +
A history of the expo website and software was published in Cambridge Underground 1996. A copy of this article Taking Expo Bullshit into the 21st Century is archived here. +
[Philip Sargent, 1 June 2020] +
I don't think writing our own object/SQL code is sensible: +there is such a lot going on we would create a large volume of software even if we stick close to the metal. +[I could well be wrong. That is Option 1.] + +
+We keep the same architecture as now, and incrementally replace modules that use django/SQL with direct object storage of collections using pickle(), shelve() and json(). +Concurrency is not a problem as all data is read-only. +We keep the url-rewriting and html-template things in django.[and migrate the unit-tests (a recent innovation) from django to be run stand-alone.] +
+This means that the "django-ness" part of troggle becomes quite small. +The more modules we replace, the easier it becomes for new people to work on it - but also the easier it becomes to migrate it to newer django versions. Or the easier it becomes to move entirely from django to Jinja2 + a URL-router + a HTTP-request/response system. +The data flow through the system becomes obvious to any python programmer with no django knowledge needed. +
+[This could be harder than it looks if cross-referencing and pointers between collections become unmaintainable - a risk we need to watch.] +
+Being memory-resident, we get a 20x speed increase. Which we don't need. + +
+So the proposed Option 2 looks a bit like this (django is the "flawed supplier" and pickle() is the "new supplier")
+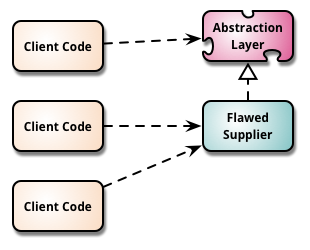 Migrate to Replacement Abstraction Layer
+
+
Migrate to Replacement Abstraction Layer
+
+
+We also use a noSQL db with a direct and easy mapping to python collections. +[This needs to be explored, but I suspect we don't gain much compared with the effort of forcing maintainers to learn a new query language. Shelve() is already adequate.] + +
We need to de-cruft troggle *first*: remove 'good ideas' which were never used, trim redundancies and generally reduce it in size significantly. +
+We should have a good look at modifying everything so that we do not read in every survey station. This means making a list of functions that we will drop and some we replace by parsing cavern output and some we calculate during importing/reading svx files. + +
+Documentation is the key to keeping troggle in a state where someone can pick it up and do a useful week's work, e.g. extracting the parsed logbooks to use shelve() storage throughout instead of SQL. The next time someone like Radost comes along during the next 5 years we want to be able to use them effectively. +
+New functionality: e.g. making the whole thing GIS-centric is a possibility. +A GIS db could make a lot of sense. Not in scope for this discussion. +
There is not yet a front-end (javascript) framework on the client, i.e. a phone app or webpage, which is stable enough for us to commit effort to. Bits of troggle use very old jQuery ("edit this page", and the svx file editor) , and Flask looks interesting, but maybe in 2025 we could see a good way to move all the user interface to the client and just have an API on the server. + +
We will also need an API now-ish, whatever we do, so that keen kids can write their own special-purpose front-ends using new cool toys. Which will keep them out of our hair. +
Andy Waddington, who wrote the first expo website in 1996, mentioned that he could never get the hang of Django at all, and working with SQL databases would require some serious book-revision: +
+So a useful goal, I think, is to make 'troggle2' accessible to a generic python programmer with no specialist skills in any databases or frameworks. Put against that is the argument that that might double the volume of code to be maintained, which would be worse. Nevertheless, an aim to keep in mind. + +But even 'just Python' is not that easy. Python is a much bigger language now than it used to be, with some esoteric corners. (Some of which could be very useful, such as the self-testing unit test +capability: docs.python.org/3.8/library/doctest ) + + + +
Read the proposal: "Troggle: a novel system for cave exploration information management", by Aaron Curtis. But remember that this paper is an over-ambitious proposal. Only the core data management features have been built. We have none of the "person management" features, none of the "wallet progress" stuff and only two forms in use: for entering cave and cave entrance data.
ALSO there have been tables added to the core representation which are not anticipated in that document of this diagram, e.g. Scannedimage, Survexdirectory, Survexscansfolder, Survexscansingle, Tunnelfile, TunnelfileSurvexscansfolders, Survey. See Troggle data model python code (15 May 2020). +
Read the proposal: "Troggle: a novel system for cave exploration information management", by Aaron Curtis. But remember that this paper is an over-ambitious proposal. Only the core data management features have been built. We have none of the "person management" features, none of the "wallet progress" stuff and only two forms in use: for entering cave and cave entrance data. + +
 +Troggle is written in Python (about 9,000 lines including comments) and is built on the Django framework. Before starting to work on Troggle it might be a good idea to run through an initial install and exploration of a tutorial Django project.
+
+
+Troggle is written in Python (about 9,000 lines including comments) and is built on the Django framework. Before starting to work on Troggle it might be a good idea to run through an initial install and exploration of a tutorial Django project.
+
+
+ +Django is the thing that puts the survey data in a database in a way that helps us write far less code to get it in and out again, and provides templates which make it quicker to maintain all the webpages. + + +
 +
+To understand how troggle imports the data from the survex files, tunnel files, logbooks etc., see the troggle import (databaseReset.py) documentation.
The following separate import operations are managed by the import utility (databaseReset.py):
Open issues being worked on:
It concentrates on showing how to find and fix import errors so that the troggle-generated webpages are complete and not full of gaps.
Intended audience: Ideally someone who is not a python programmer will be able to use this page to help them fix import errors.
Also here we will explain the useful diagnostic pages such as
-experimental
-pathsreport
-survey_scans
-/admin/core/dataissue/
-tunneldata
-statistics
-people
+experimental
+pathsreport
+survey_scans
+/admin/core/dataissue/
+tunneldata
+statistics
+people
Troggle runs much of the the cave survey data management, presents the data on the website and manages the Expo Handbook. -
This part of the handbook is intended for people maintaining the troggle software. Day to day cave recording and surveying tasks are documented in the expo "survey handbook" +
We have several quite different sorts of cavers who interact with troggle: +
These are some of the "use cases" for which troggle needs to be (re)designed to cope with. + +
This troggle manual describes these:
Assumptions (points to necessarily agree upon) -
Two page preliminary design document for 'caca' (Cave Catalogue) rev.2 2013-07-26 by Wookey (copied from http://wookware.org/software/cavearchive/caca_arch2.pdf) - - -
This is likely to change with structural change to the site, with style changes which we expect to implement and with the method by which the info is actually stored and served up.
-... and it's not written yet, either :-)
-CUCC still has an archive list of things that at one time were live tasks: -from camcaving.uk/Documents/Expo/Legacy/Misc/... and that page is reproduced in the table below (so don't worry if the URL link goes dark when CUCC reorganise their legacy pages). -
Troggle is a system under development for keeping track of all expo data in a logical and accessible way, and displaying it on the web. At the moment, it is [no longer] under development at http://troggle.cavingexpedition.com/ - -But note that this is Aaron's version of troggle, forked from the version of troggle we use. Aaron uses this for the Erebus expedition. -
-Note that the information there is incomplete and editing is not yet enabled. -
-Feature |
- Old expo website |
- Troggle: planned |
- Troggle: progress so far |
-
|---|---|---|---|
Logbook |
- Yes; manually formatted each year |
- Yes; wiki-style |
- Start at the front page, troggle.cavingexpedition.com/ [1] and click to logbook for year. The logbooks have been parsed back to 1997. |
-
Cave index and stats generated from survex file |
- Yes |
- Yes |
- - |
Survey workflow helper |
- Yes; minimal. surveys.csv produced an html table of whose surveys were not marked “finished” |
- Yes. Makes table of surveys per expo which shows exactly what needs doing. Displays scans. Integrated with survex, scanner software, and tunnel. |
- See it at troggle.cavingexpedition.com/survey . Be sure to try a recent year when we should have data. Survex, scanner, and tunnel integration still needs doing. |
-
QM lists generated automatically |
- Depends on the cave. Each cave had a different system. |
- Yes; unified system. |
- Done, but only 204 and 234 Qms have been imported from old system so far. No view yet. |
-
Automatic calendar for each year of who will be on expo when |
- No, manually produced some years |
- Yes |
- Done; see troggle.cavingexpedition.com/calendar/2007 (replace 2007 with year in question) |
-
Web browser used to enter data |
- No |
- Yes |
- Everything can be edited through admin, at troggle.cavingexpedition.com/admin . Ask aaron, martin, or julian for the password if you want to have a look / play around with the admin site. Any changes you make will be overwritten. Eventually, data entry will probably be done using custom forms. - |
-
Cave and passage descriptions |
- Yes, manually html coded. |
- Yes, wiki-style. |
- Not done yet. |
-
Expo handbook |
- Yes, manually html coded. |
-
|
- Not done yet. |
-
Table of who was on which expo |
- Yes |
- Yes |
- Data has been parsed, this view hasn't been written yet. |
-
Signup form, System for keeping contact, medical and next of kin info |
- No |
- Yes |
- Signup form should be ready by 20 Jan. |
-
Automated photo upload and gallery |
- No; some manual photo galleries put together with lots of effort |
- Yes |
- Photo upload done, gallery needs writing. |
-
Search |
- No |
- Yes |
- - |
-ckan is something like this - could we use it? -esri online - -CUCC (troggle) http://cucc.survex.com/ - this site. -virgina caves database (access+arcgis) (futrell) -each country database -Austria (spelix) ( www.spelix.at/ -UK cave registry -mendip cave registry: (access) www.mcra.org.uk/wiki/doku.php -White mountains database (gpx + google earth) -Matienzo (?) -Fisher ridge (stephen cladiux) -hong meigui (erin) (ask erin later) -Wikicaves www.grottocenter.org/ - multilingual, slippymap, wiki data entry. includes coordinate-free caves. - focus on sport-caving type info (access, basic gear list, overall description, bibliography) - e.g. australians only publish coordinates to nearest 10km -turkey www.tayproject.org. - -www.uisic.uis-speleo.org/contacts.html change link. no-one looks for list of databases under 'contacts' - -graziano ferrari northern italy list (access + google earth) -- -
-Generally I'd like to find some people (geeks) that share these technical -ideas: (1) store things in a file system, (2) use XML, (3) do not aim too high -(do not try designing a general system for handling all caving-related data -for the whole world). - -If I could find some people that agree with this, then we could try to reach a -compromise on: -(1) how do we store our data in a file system, -(2) how do we use this XML (let's do a common spec, but keep it simple) -(3) how do we aim not too high and not end up dead like CaveXML :) - -After we do that, everyone goes away to do their own projects and write their -own code. Or maybe we have some degree of co-operation in actually writing the -code. Normal life. But the idea is that all geeks working on "cave inventory" -and systems making extensive use of cave inventories try to adhere to this -framework as much as possible. So that we can then exchange our tools. - -I think things like "which revision system do we use" or "do we use web or -Python" are really secondary. Everyone has their own views, habits, -backgrounds. - -My idea is to work on this in a small group (no more than a few persons) - to -get things going fast, even if they are not perfect from the beginning. If it -works, we try to convince others to use it and maybe push it through UIS. -- -
-forms ------ -1) members read/write folk.csv and year/members -2) cave read/write cave_data, entrance_data, surveys/pics -3) trips -> logbook , QMs, or surveys (more than one survey or location possible) -4) logbook reads/write year/logbook -5) survey -6) prospecting app - -forms show who is logged in. - -databases ---------- -trips, read from - logbook entry - folder year#index - .svx files - description - QMs - -members (cache from form) - -caves - caves_data - entrance_data - -storage: - expoweb - data/ - cave_entrances - caves - descriptions - - loser - foo.svx -- - -
-frontpage ---------- -quick to load: -Links: - Caves number, name, location - Years - Handbook - Data Entry - Main Index - -Slippy map: - Indexes to cave page - -Cave page: - Access, description, photos, QMs, Survey - -Years: - Logbooks/surveynotes/survexdata/people matrix - Documents - -Data Entry: - Logbook entry - Survey data - Survey Notes - Cave description - QMs - Photos - New cave - -Backend datafiles: - caves/ - cave_entrance - cave_data - directory of info - - years/ - year/ - logbook - pubs/ - reports - admin/ - lists - who_and_when - travel - jobs - - surveyscans/ - year/ - index - #num - handbook/ - (all static info) - -Storage: - non-html or > 280K go in 'files' (PDF, PNG, JPEG, DOC, ODF, SVG) - convert small 1024x768 version into website by default. (matching structure? --
Since 2008 we have been keeping detailed records of all data management system updates in the version control system. Before then we manually maintained a list of updates which are now only of historical interest. -
A history of the expo website and software was published in Cambridge Underground 1996. A copy of this article Taking Expo Bullshit into the 21st Century is archived here. +
A history of the expo website and software was published in Cambridge Underground 1996. A copy of this article Taking Expo Bullshit into the 21st Century is archived here.